
MLOps: Engineering Intelligence at Scale – A Practitioner's Blueprint
MLOps is emerging as a critical discipline that bridges ML development and production operations, ensuring scalability, reliability, and alignment with business goals This practitioner’s blueprint outlines how to build scalable ML systems from central model development to edge deployment, while maintaining observability, automation, and governance. It emphasizes a platform-engineering mindset: treat your MLOps pipeline as a product, continuously iterating based on user feedback and evolving enterprise needs. By leveraging modular architectures, CI/CD, model registries, and robust data pipelines, organizations can operationalize AI with confidence and efficiency.
Adellion
MLOps: Engineering Intelligence at Scale – A Practitioner's Blueprint
In today’s machine learning landscape, model accuracy is just the beginning. The real challenge lies in making the model production-ready and keeping it relevant amid ongoing changes.
That’s where MLOps comes in—not just as a buzzword but as an engineering philosophy that combines DevOps with the dynamic lifecycle of ML. While core ideas from frameworks like Google’s MLOps whitepaper provide valuable insights, I have developed and implemented a refined MLOps architecture that directly addresses modern ML scalability, reproducibility, and observability.
Let’s walk through how this comprehensive MLOps architecture enables smooth ML system operations.
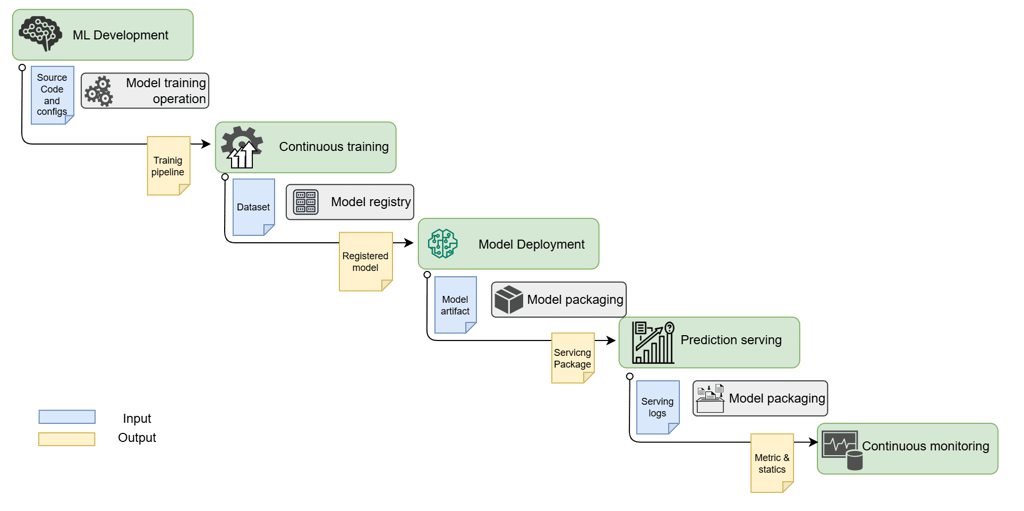
The Engineered MLOps Lifecycle
Unlike traditional software, ML systems are closely tied to constantly evolving data. So, our architecture must support iteration, automation, and traceability. Here's how we designed it:
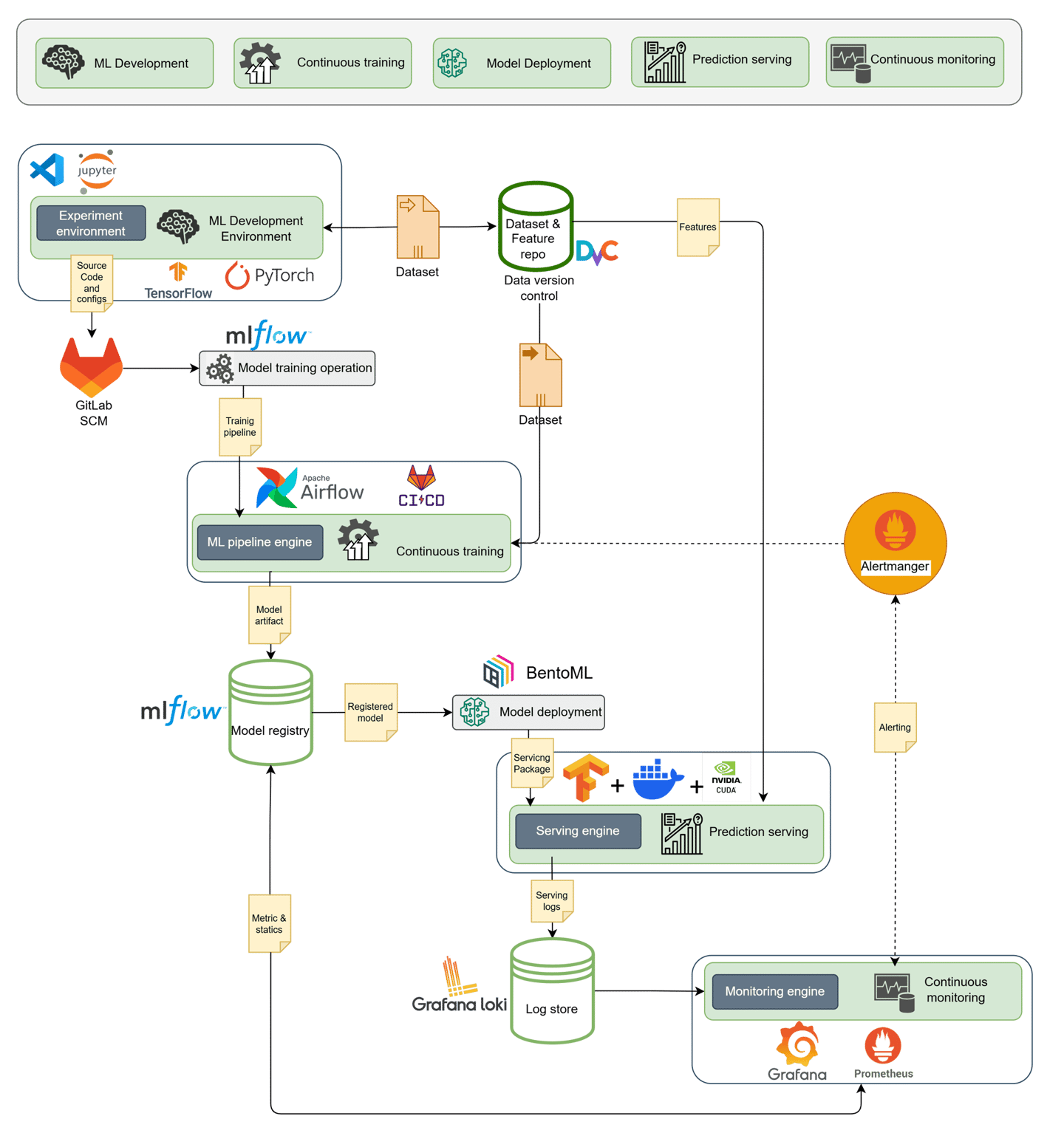
1. ML Development Environment
• Tools like Jupyter, TensorFlow, and PyTorch empower data scientists to experiment.
• Experiments are versioned in GitLab, tracking source code, parameters, and notebooks.
• This phase is where ML recipes are built—from dataset selection to feature extraction.
2. Data Versioning & Feature Store
• Raw and processed datasets are stored in a DVC-powered repo, ensuring reproducibility.
• Feature pipelines standardize transformation logic across training and inference.
• Every dataset snapshot and derived feature is tracked, promoting reusability across teams.
3. Continuous Training with Pipelines
• Apache Airflow, integrated with CI/CD systems like GitLab CI, orchestrates ML workflows.
• Training pipelines retrain models on schedule or when data drifts are detected.
• Each run logs metadata to MLflow, ensuring lineage tracking and rollback capabilities.
4. Model Registry & Deployment
• Once validated, trained models are versioned in the MLflow Model Registry.
• Deployment is automated using BentoML, containerizing the model with deployment metadata.
• Serving is container-native (Docker + NVIDIA CUDA), offering flexibility for edge, GPU, or cloud deployment.
5. Prediction Serving with Observability
• Real-time inference is managed through a serving engine with auto-scaling features.
• Logs are shipped to Grafana Loki for debugging and audit purposes.
• A/B testing, shadow deployments, and rollback policies are integrated into the deployment pipeline.
6. Monitoring & Alerting
• Prometheus gathers inference metrics—latency, throughput, and drift indicators.
• Grafana visualizes dashboards for engineering and business teams.
• Alertmanager notifies teams about performance issues or prediction anomalies.
Why This Architecture Works
Modular yet Integrated: Each component (Airflow, MLflow, BentoML) is top tier, combined into a unified pipeline with clear interfaces.
Data-Centric: Reproducibility extends beyond code—every dataset and feature used in training or deployment is versioned and traceable.
Scalable: GPU-based training and containerized deployment pipelines ensure the system can handle high-throughput use cases.
Observability-First: We prioritize monitoring and logging as essential components, because “model in prod” is just the beginning.
From Prototype to Production, Continuously
Deploying a model isn’t a heroic last-mile effort anymore. With this MLOps setup, training, deployment, and monitoring become routine, automated processes.
And that’s the true transformation—MLOps turns ML from a research project into a production-grade, continuously evolving system.
Let’s Talk
Are you navigating the complexities of ML in production? Or building your own MLOps platform? I’d love to hear how others solve these challenges—and where we can raise the bar together.
#MLOps #MachineLearning #DevOps #AIOps #MLEngineering #MLOpsArchitecture #DataOps #incedo #advellion
advellion
Transforming ideas into scalable digital solutions.
Insights
Automation
Address. 405, Vedanta, Wakad, Pune - 411057
+91 8983299219
© 2025. All rights reserved.